Оглавление
- Оглавление
- Архитектура
- Управление доступом к БД
- Пользовательские права
- Роли
- Пользователи
- Группы ролей - Работа с PostgreSQL
- Транзакции
- ACID
- Atomacity (атомарность)
- Consistency (согласованность)
- Isolation (изолированность)
- Durability (долговечность) - Выполнение операций и восстановление данных
- Резервное копирование
- Репликация
- Масштабирование и шардирование
Архитектура
Архитектура ANSI_SPARC
Включает в себя три уровня.
1. Внешний (пользовательскй) уровень - представляет их данные так, как их видят конечные пользователи. У разных пользователей могут быть разные представления одной и той же базы - например, один видит только часть таблиц или полей.
- Реализуется через представления
- На этом уровне пользовательские запросы и интерфейсы
2. Промежуточный (концептуальный) уровень - описывает структуру базы данных. Здесь задаются таблицы, структура таблиц, связи между ими, схемы. Определяет логическую структуру данных (столбцы, типы данных, связи). Это описание бд в целом без привязки к тому, как она хранится.
3. Внутренний (физический) уровень - описывает, как физически хранятся данные. С этим уровнем пользователи напрямую не работают.
- Реализуется через файлы данных, индексы, WAL
- Тут происходит управление страницами и блоками
- Стратегии хранения и доступа к данным.
PostgreSQL следует этой модели
- Пользователь видит таблицы и представления (внешний уровень)
- Админ определяет схемы и отношения (концептуальный)
- Система управляет табличными пространствами, файлами, индексами (физический)
Структура СУБД
- На уровне структур в основной памяти ЭВМ
- На уровне процессов в ОС
- На уровне структуры хранилища данных в ФС
Кластер БД - множество бд, управляемых экземпляром сервера БД
Инстанс - процессы СУБД + разделяемая память
Архитектура PostgreSQL
Постргрес - объектно-реляционная клиент-серверная СУБД.
Общая идея: клиенты -> Серверные процессы -> Память -> Диск
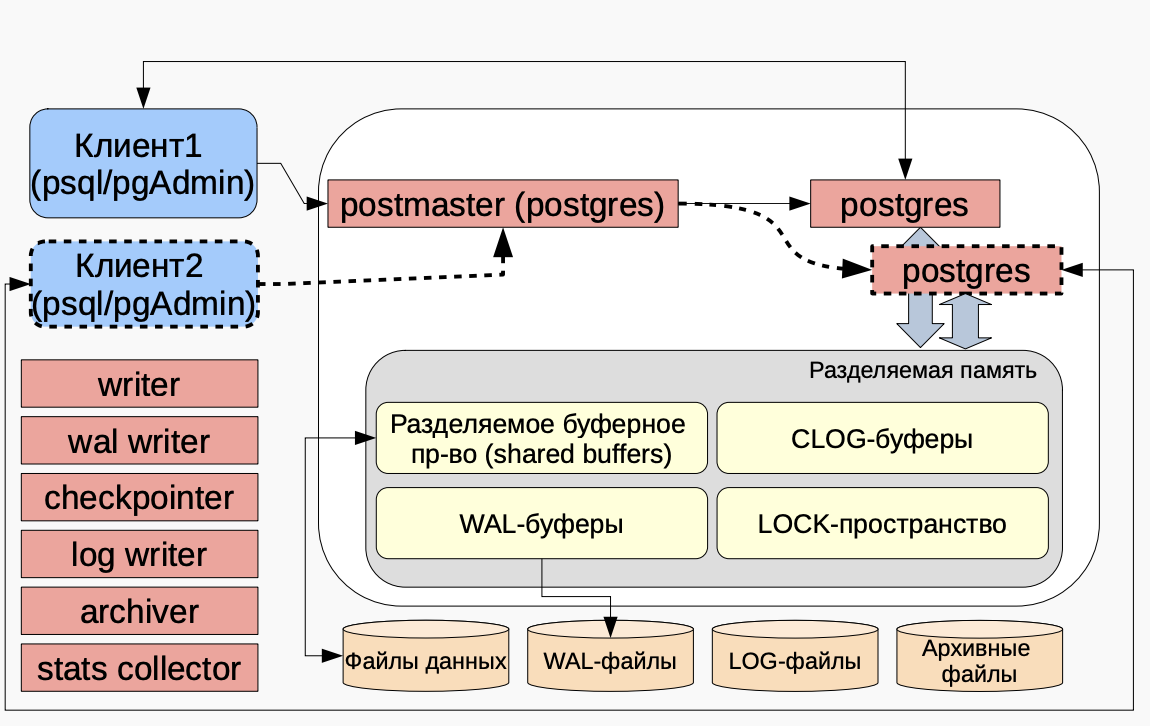
psql, pgAdmin- клиенты, отправляющие какие-то запросы в бдpostmaster- представляет сервер PostgreSQL, отвечает за его запуск и остановку. Создает серверные процессы для обработки соединений. Управляет данными одного кластера БД (БД или несколько БД, расположенных по определенному адресу в ФС)- Процессы
postgres- это процессы под конкретных клиентов. Каждому клиенту свой процесс, выполняющий SQL Разделяемая память- Разделяемое буферное пространство (Shared Buffers) - кэш данных (страницы таблиц)
- WAL buffers - буфер журнала изменений
- CLOG buffers - статус транзакций
- Lock space - информация о блокировках
Диск- Файлы данных - сами таблицы
- WAL-файлы - журнал изменений
- LOG-файлы - логи сервера
- Архивные файлы - сохраненные WAL для резервного копирования
Фоновые процессыbackground writer- записывает dirty pages на диск. Записанные страницы помечает чистыми. Облегчает работу checkpointer.- Параметр bgwriter_delay - он задает как часто фоновый процесс просыпается и записывает данные на диск. По умолчанию 200мс
wal writer- пишет wal на дискcheckpointer- делает чекпоинт (синхронизация с диском)- Чекпоинт - точки в последовательности транзакций, в которые произведена синхронизация результатов выполненных операций с файлами на диске.
- Чтоб ее создать:
- WAL-буфер синхронизируется с диском
- Грязные страницы записываются на диск
- Контрольная точка фиксируется в логах
- Создается, когда заполнен max_wal_size или через время checkpoint_timeout (по умолчанию 300 сек) - зависит от того, что будет раньше
log writer- записывает сообщения, отправленные в stderr в лог-файлы. Для работы нужно, чтобы был установлен параметр logging_collectorarchiver- копирует созданные WAL-файлы в указанное место. По умолчанию выключенstats collector- собирает статистику в промежуточные файлы для использования другими процессами (pgstat)- Директория с временными файлами определяется параметром stats_temp_directory
Разделяемое буферное пространство (Shared Buffers)
- Хранит копии блоков данных, считанных из файлов данных
- Служит для минимизации числа операций обмена с диском
- Если нужного блока (страницы) нет в SB, он читается с диска и помещается в SB
- Совместно используется всеми фоновыми и пользовательскими процессами экземпляра
- Можно настроить через shared_buffers
- По умолчанию 128 МБ
WAL buffers
- WAL - write ahead log
- Хранит инфу об изменениях данных в БД - записи XLOG
- Изменениям присваивается LSN - log sequence number
- Эта информация используется для воссоздания актуального состояния данных в случае восстановления бд
- Настраивается через параметр wal_buffers
CLOG buffers
- CLOG - commit log
- Хранит данные о статусе проведения транзакций (в процесе, закончена и тп)
- Размер автоматически устанавливается СУБД
- Доступен серверным процессам
Lock space
- Хранит данные о блокировках, использующихся экземпляром БД
- Данные о блокировках доступны всем серверным процессам
- Можно настраивать через max_locks_per_trasaction
Буферное пространство процессов (неразделяемая область памяти процессов)
- Для каждого серверного пользовательского процесса выделено пространство для осуществления операций. По умолчанию 4 МБ
- Может быть различных видов:
- vacuum buffers
- рабочая память (work mem) - DISTINCT, ORDER BY, JOIN
- вспомогательная рабочая память (maintenance_work_mem) - REINDEX
- temp_buffer - для работы с временными таблицами
В режиме выделенного сервера каждому пользовательскому процессу создается свой "персональный" серверный
В режиме разделяемого сервера для каждого пользвательского процесса серверный процесс выделяется диспетчером из специального пула. Пул управляется с помощью pgBouncer. Он держит пул соединений, переиспользует их и ускоряет подключение.
Системный каталог
В постгре есть возможность получать данные о метаданных: когда была создана таблица, сколько и какие в ней атрибуты, какие индексы связаны с таблицей. Для доступа к метаданным используются таблицы и представления - системные каталоги.
У каждой БД есть схема pg_catalog, в ней каталоги. относящиеся к этой БД
Работа с системным каталогом
- Использование напрямую
SELECT * FROM pg_*:
SELECT count(*) FROM pg_stat_activity- pg_database - инфа о бд в кластере (один для кластера)
- pg_class - инфа о таблицах, представлениях, индексах и тп
- pg_tables инфа о таблицах текущей бд - у каждой БД свой.
- Использование INFORMAION_SCHEMA
- Представления, через которые можно получить данные системных каталогов. Являются частью SQL стандарта.
SELECT Table_Name FROM information_schema.TABLES;
- Мета-команды psql
\d MyTable- посмотреть структуру таблицы\d objectName- инфа об объекте из бд\di- посмотреть созданные индексы.
oid - идентификатор объекта в постгрес
pg_attribute- каталог с инфой о колонках таблицы. (поле attrelid - oid таблицы, к которой относится эта колонка; attname - имя колонки). Для типа oid существуют различные типы-алиасы для упрощения работы (regclass - oid таблицы, позволяет получить значение oid по названию таблицы)
Схема
- Используются для логической группировки объектов в БД. У каждой бд есть схема public
- Полное имя в постгре выглядит как:
dbName.schemaName.objectName - Объекты можно испоьзовать без полного имени, тогда используется search_path - последовательность схем, которая будет использована для идентификации объекта, когда используется неполное имя
- Схемы рассматриваются в порядке из search_path. Первая схема используется для создания объектов и является текущей.
- pg_temp и pg_catalog автоматически добавляются перед первой указанной указанной схемой (порядок можно переопределить)
- Изменять нужно осторожно, тк меняется контекст выполнения запросов (разрешение имен)
- show serch_path
Управление доступом к БД
Пользовательские права
Разным категориям юзеров должны предоставляться разные возможности для управления различными объектами БД
Возможности - обеспечение доступа (или выполнения другой операции) с таблицами, представлениями, создание пользователей.
Представляемые возможности определяются привилегиями:
- Системные - описывают возможность осуществления операций над БД
- Для взаимодействия с объектами - операции над различными объектами. С разными объектами связаны различные привилегии.
SELECT- чтение данных из таблицы/представления
INSERT- добавление данныхUPDATE- изменение данныхDELETE- удаление данныхTRUNCATE- очистка таблицыREFERENCES- создание внешнего ключаTRIGGER- создание триггераCREATE- создание объекта (схемы, таблицы и т.д.)CONNECT- подключение к БДTEMPORARY- создание временных таблицEXECUTE- выполнение функции/процедурыUSAGE- использование схемы, последовательности и т.д.ALL PRIVILEGES- все привилегии сразу
GRANT priv1, priv2 ON table1 TO user1, user2...
Владелец объекта - пользователь (роль), создавший объект. Обладает привилегиями ALTER и DROP для своего объекта по умолчанию
Роли
Привилегии отражают конкретную возможность.
Роли - именованные наборы привилегий, позволяющие управлять объектами и бд на более высоком уровне. Могут выступать в качестве пользователей.
Роль конфигурируется на уровне кластера. Назначение и привилегии могут отличаться в разных БД. Имя роли уникально для кластера.
CREATE ROLE ... WITH LOGIN PASSWORD 'PSWD'
CREATE ROLE ... CREATEROLE
ALTER ROLE, DROP ROLE
Эти команды могут использовать суперпользователи и роли с CREATEROLE (не на суперпользователях)
Пользователи
При установке кластера создается админ postgres
Пользователи созданы для отображения именованных пользователей системы. Они могут быть созданы суперпользователем и пользователем с ролью CREATEROLE.
CREATE USER... == CREATE ROLE ... WITH LOGIN
При создании БД создается роль public. Он назначается всем пользователям и ролям - определяет права пользователей и ролей по умолчанию к разным объектам.
Настройка через pg_roles
В постгре нет отдельных пользователей. Пользователь - это просто роль с правами входа (LOGIN). Ну и пользователи обычно не используются как группы.
Настройка ролей:
- SUPERUSER - пользователь может действовать как суперпользователь кластера (все права на все объекты). Можно создать несколько суперпользователей
- NOSUPERUSER - убирает возможности SUPERUSER
- CREATEROLE - позволяет создавать роли
- CREATEDB - позволяет создавать бд в кластере
- PASSWORD - установить пароль (
CREATE USER ... WITH PASSWORD 'PSWD') - PASSWORD NULL - запретить пользователю вход по паролю
- CONNECTION LIMIT n - задать ограничение по числу подключений для пользователя
- VALID UNTIL - установить срок действия роли (пароля этой роли)
Для подключения к БД роль должна быть: - LOGIN
- содержать привилегию CONNECT на нужную БД
- разрешение в pg_hba.conf
Группы ролей
Роли можно объединять в группы для более гибкого управления ими. При добавлении пользователя в группу пользователь наследует ее привилегии.
CREATE ROLE students;
GRANT INSERT ON table_name TO students;
GRANT students TO user1;
Таким образом первый юзер получает все права роли студенты. Это используется для того, чтобы не выдавать права каждому пользователю отдельно, а управлять ими централизованно.
Админ группы ролей - человек, который может управлять группой (добавлять, удалять участников). Эта роль не дает ему всех привилегий, но позволяет управлять своей группой.
GRANT students TO user1 WITH ADMIN OPTION
INHERIT - поведение по умолчанию. В этом случае пользователь автоматически получает права всех ролей, в которые входит
NOINHERIT - пользователь не получает права автоматически. Ему нужно явно переключиться на нужную роль SET ROLE sudents. Это используется для разделения обычных и привилегированных действий. (можно сидеть как обычный юзер, а потом переключиться на админа и тыкаться как админ). Указывается при создании роли (не группы)
Поиск привилегий идет так:
- Поиск среди привилегий роли
- Поиск среди родителей (если inherit), поиск среди прародителей (если у родителей inherit)
- Есть ли привилегия для public
Для отмены привилегий: REVOKE priv1 ON table1 To user1
Работа с PostgreSQL
Установка и запуск PostgreSQL
Есть два варианта:
- Графический установщик
- Использование утилит
- Использование подготовленных бинарных файлов (разные сборки для разных ОС)
- Компиляция исходых кодов (make). Нет сборки для используемой ОС. Нужна самая последняя версия/версия с внесенными изменениями.
Устанавливаются базовые компоненты PSQL
- Сервер postgresql
- Клиент postgresql-client
- contrib, docs и другие компоненты
Процесс установки
- Установка (сборка) базовых компонентов (пакетов):
sudo apt install postgresql-xx postgresql-client-xx .. - Создание системного пользователя postgres:
adduser postgres,mkdir [PGDATA],chown postgres [PGDATA] - Задание переменных окружений: PGDATA, ...
- Инициализция кластера [/pg_path]/bin/initdb [-D PGDATA_path]
- Запуск экземпляра кластера БД
- postgres [-D PGDATA_path]
- pg_ctl [-D PGDATA_path] -l logfile start
- Сервис: sudo service postgresql start
Инициализация кластера initdb
- Создает структуру директорий PGDATA
- Создает стандартные БД, которые можно использовать без создания своих баз
- Задает локаль и кодировку, которая будет использоваться кластером БД
initdb [-D PGDATA_path],pg_ctl initdb
Инициализация
Базы данных доступные после установки:
- Пользовательская БД (postgres) - принадлежит админу БД - пользователю postgres
- template1
- клон template1 - template0
Создается суперпользователь - по умолчанию совпадает с именем пользователя, запустившего initdb. Можно задать имя через initdb -U name
templte0, template1
- Изначально они идентичны.
- template0 - служит в виде резервной копии
- template1 - используется в качестве шаблона при создании других БД, к ней можно подключаться и ее можно изменять.
- Можно создать свою БД, которая будет использоваться в качестве шаблона
- Если внести изменения в template1 - они будут применены и для баз, созданных на его основе. Т.е. если создать в ней таблицы/поставить расширения/настроить права - это все появится во всех бдшках
- К template0 нельзя подключиться (она резервная). Она используется если мы совсем засрали template1 или хотим прям чистую бд. В том числе если нам например надо сменить кодировку.
- В pg_database есть поля
- datistemplate - можно ли использовать как шаблон (у обоих тру)
- datallowconn - можно ли подключаться (у t0 false, у t1 true)
Запуск сервера базы данных
[/pg_path]/bin/postgres [-D pgdata_path]
Можно заранее установить переменную PGDATA:
PGDATA = ...
esport PGDATA
postgres
! PGDATA должна быть проинициализирована перед запуском постгри
Утилита pg_ctl
Нужна для упрощения взаимодействия с постгрей. Можно запускать (по умолчанию в фоне), останавливать, перезапускать кластер
pg_ctl start -l logfilepg_ctl status [-D PGDATA_path]- Можно для инициализации кластера
pg_ctl [-D PGDATA_path] initdb
Подключение к БД PostgreSQL
Варианты клиентов:
- psql - интерактивный терминал, так называемая база
- pgAdmin - графический клиент, доступный на все оси (но это не точно)
- клиенты, использующие libpq
Для подключения к БД роль должна быть:
- LOGIN
- содержать привилегию CONNECT на нужную БД
- разрешение в pg_hba.conf
Подключение к серверу БД
- Запуск сервера
postgres -p 2222 -D /home/myuser/pgd/data - Подключаем клиент
psql -p 1234 - Экземпляр проверяет, может ли клиент получить доступ
- Если проверка прошла успешно, создается серверный процесс для обработки соединения данного клиента
pg_hba.conf
- В этом файле задаются способы подключения для различных пользователей к различным базам данных
- Создается при работе initdb
- По умолчанию лежит в PGDATA
- Можно поменять через hba_file параметр:
- При запуске postgres
- В postgresql.conf
- Каждая запись в файле определяет вид подключения для разных категорий пользователей
- Порядок расположения записей влияет на права:
- Чтение происходит последовательною Применяется первая подходящая строка.
- pg_hba.conf читается во время запуска
- Если файл изменен:
- pg_reload_conf()
- pg_ctl reload
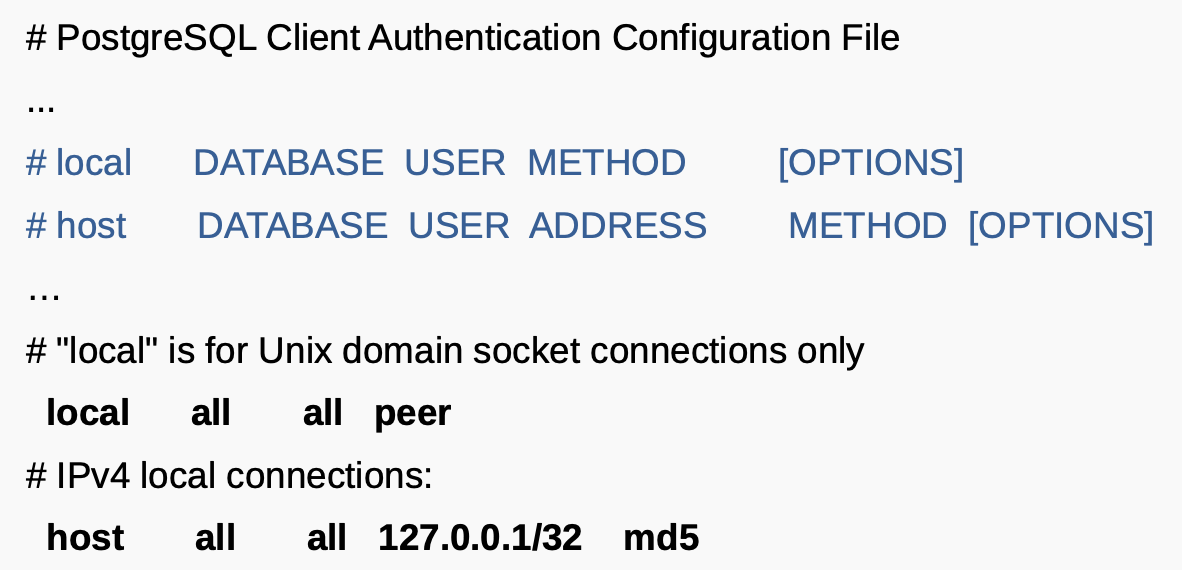
- local - локальный UNIX-сокет
- psql без имени хоста, используется libpq подключается пользователь системы к бд с тем же именем, а так же есть пользователь бд с тем же именем)
- клиент и сервер на одной машине
- параметр unix_socket_directories
- host - TCP/IP соединение
- Указывается xост и порт
- Предполагается, что задан параметр PGDATA
Методы подключений:
- trust - предоставить доступ всем из данной категории
- по паролю(scram-sha-256, md5, password). Смена пароля
- Изменение роли
- \password
- ident - похоже на peer, но для host соединения
- peer - сравнивается пользователь ОС с пользователем в БД
- Правила отображения пользователей можно задать в pg_ident.conf и параметр map в pg_hba.conf
- Только для local
Создание БД в PSQL
- CREATE DATABASE newDb [WITH опции]
- createdb - утилита в директории [/postgresql]/bin:
create -h host -p port -U user [options] newDb - Чтобы создать базу пользователь должен быть суперпользователем/иметь роль CREATEDB
Создание из шаблона
По умолчанию клонится template1
Но можно и другую бд использовать: CREATE DATABASE newDb TEMPLATE oldDb или проще createdb -T oldDb newDb
Чтобы база могла быть шаблоном нужно, чтобы к ней не было подключений других пользователей.
В системном каталоге pg_database есть поля
datistemplate- бд создана во имя бытия шаблоном. Может быть использована как шаблон владельцем, суперюзерами и ролью CREATEDBdatallowconn- можно ли подключаться (false - запрещены новые подключения)
Файловая структура и конфигурация PSQL
PGDATA - путь к директории данных кластера, установлена заранее
global- содержит таблицы уровня кластера (pg_database)pg_wal- директория с wal файлами (кто бы мог подумать)pg_xact- директория с данными о коммитах транзакций (CLOG)base- файлы данных БД кластераsudo ls /PGDATA/base- получим список oid, соответствующих базам
Утилита oid2name - для просмотря имен по oid или filenode
Файлы данных
- Объектам БД - соответствуют файлы данных
- Если до гигабайта - объекту соответствует 1 файл данных
- Если больше - соответствуют файлы-сегменты
- Находятся в $PGDATA/base в директории соответствующей бд
Базовые конфиг файлы:
- стандартный путь до них:
/etc/postgresq/version/main/ postgresql.conf- базовый файл для хранения настроек- Создается при работе initdb
- По умолчанию в PGDATA
- Представляет из себя набор параметров (имя, значение):
shared_bussers=128MB - Определяют значения для всего кластера
postgresql.auto.conf- динамически изменяемые настройки (через ALTER SYSTEM)pg_hba.conf- конфига подключений к бдpg_ident.conf- файл отображения имен
Изменение конфигурационных параметров:
postgresql.conf / ALTER SYSTEM- на уровне кластераALTER DATABASE- изменить параметр на уровне бд (применяется при запуске новой сессии)ALTER ROLE- переписать 1. и 2. на уровне пользователя (тоже при запуске новой сессии)SET- изменить для сессии (`SET param TO value /DEFAULT)- Параметры можно задать в команде запуска сервера БД (postgres) - для переписи парметров postgresql.conf
Табличные пространства
Табличные пространства позволяют задать пути (директорию в фс), где будут храниться объекты БД (вне PGDATA)
Это позволяет управлять физическим расположением объектов БД
- У табличных пространств есть имя
- Просмотр размера - функция
pg_tablespace_size('name') - Системный каталог - pg_tablespace
- $PGDATA/pg_tblspc содержит симлинки на директории внешних табличных пространств
- Их можно задать для разных объектов БД: таблиц, индексов, последовательностей, представлений
CREATE TABLESPACE newTs LOCATION 'diskA/dir' CREATE TABLE STUD ( id integer NOT NULL ) TABLESPACE newTs; ```
Стандартные тс:
pg_default- соответствует директории base в PGDATA. Тут по умолчанию файлы данных, соответствующие объектам бд.pg_global- соответствует директории global в PGDATA- pg_database, pg_authid, pg_tablespace, некоторые другие каталоги и индексы
Табличное пространство можно задать для БД целиком:
CREATE DATABASE TestDb TABLESPACE newTs
Его можно и поменять
ALTER TABLE STUDENT SET TABLESPACE pg_default
- pg_database, pg_authid, pg_tablespace, некоторые другие каталоги и индексы
Так накой же они нам вообще нужны?
- Можно контролировать что где хранится
- Критически важные объекты можно размещать на более быстрых физических дисках
- Если заканчивается место на жестком диске, можно использовать другой диск для размещения объектов.
Транзакции
Минутка так называемой базы для тех, кто еще хоть чуть чуть помнит ИС
- Транзакции объединяют последовательность действий в одну операцию
- Промежуточные состояния внутри последовательности операций не видны другим транзакциям
- Если что-то помещает успешно завершить транзакцию, ни один из результатов этих действий не сохранится в БД
ACID
Atomacity (атомарность)
Гарантирует, что результаты работы транзакции не будут зафиксирован в системе частично
Будут выполнены либо все операции, либо ни одной
Consistency (согласованность)
После выполнения транзакции бд должна быть в целостном состоянии
Во время выполнения транзакции согласованность не требуется
Isolation (изолированность)
Во время выполнения транзакции другие транзакции (выполняющиеся параллельно) не должны оказывать влияние на результат транзакции
Durability (долговечность)
При успешном завершении транзакции результаты ее работы должны остаться в системе независимо от возможных сбоев оборудования, системы и тд
Какими бывают транзакции:
- Неявные - субд начинает без явного указания (любое действие осуществляется в контексте некоторой транзакции)
- Явные - транзакции, которые пользователь задает самостоятельно (Begin, Commit)
- Если нет явного указания начала - любое предложение в рамках неявной транзакции
- Транзакционный DDL - особенность PostgreSQL. Многие команды DDL (CREATE, ALTER, DROP) могут быть выполнены и откачены в рамках транзакции аналогично DML. Исключение составляют некоторые операции (например,
CREATE INDEX CONCURRENTLYили работа с БД).
BASE
Альтернативой ACID для распределенных баз данных является концепция BASE (опирающаяся на CAP-теорему):
- Basically Available (Базовая доступность) — система гарантированно отвечает на любой запрос, даже при сбоях части узлов.
- Soft-state (Гибкое состояние) — состояние системы может изменяться со временем, даже без ввода новых данных, в процессе синхронизации узлов.
- Eventual consistency (Конечная согласованность) — если данные перестают изменяться, то через некоторое время все узлы придут к согласованному (консистентному) состоянию.
Она жертвует строгой консистентностью в пользу высокой доступности и производительности масштабирования.
Время и транзакции
CURRENT_TIME- Внутри транзакции вывод не изменится даже спустя час, два, больше...
- А так просто выводит час, минуты, секунды
- Возвращает время начала транзакции
clock_timestamp()- возвращает текущее время (там еще дата добавится)
+now()- просто дата и время в данный момент времени
Идентификация транзакций
- Идентификатор транзакции (xid) - назначается СУБД для каждой новой транзакции. Он уникальный. При создании/модификации записи хранится xid транзакции
pg_current_xact_id()- возвращает xid текущей транзакции (bigint)- 32 бита, беззнаковое число
Скрытые поля или где же искать этот ваш xid
xmin- xid транзакции, в рамках которой запись (копия записи) была созданаxmax- хранит xid транзакции, в рамках которой запись была удаленаcmin- идентификатор команды, создавшей записьcmax- идентификатор команды, удалившей запись
Возможные значения:
- xid - 32 бита, беззнаковое
- В простейшем случае - чем больше xid, тем позже она началась
- xid до - прошлое
- xid после - будущее
- Начинается с 3 (0,1, 2 - зарезервированы)
Могут ли закончиться? Ну тогда у нас просто заново с 3 начнется выдача. Но вообще есть такая шняга, как статус FROZEN для неактуальных записей, но про это в разделе VACUUM
Ну и быстро вспомним что у нас был такой CLOG-буфер, который хранит статус транзакций:
- N_PROGRESS
- COMMITTED
- ABORTED
- SUB_COMMITTED
Файлы его в директории pg_xact
Реализация транзакций в PSQL
- Транзакции должны удовлетворять требованиям ACID
- СУБД должна обеспечивать многопользовательский доступ
- Разные пользователи могут запрашивать и изменять одни и те же данные в одно время
- Существуют разные способы реализации транзакций:
- Могут основываться на блокировании ресурсов, синхронизации доступа к данным, создании копий данных
Как это сделано в постгре?
Реализация транзакций в постгре - MVCC
Multi-Version Concurrency Control
В постгре - Serializable Snapshot Isolation (SSI)
Особенность в том, что при изменении данных в транзакции создается новая копия данных. А существующие копии не изменяются. При выборки данных берется подходящая для данной транзакции версия данных. Но даже не смотря на это у нас все же иногда случается блокировка исполнения транзакции.
Изоляция транзакций
При параллельном доступе к данным у нас может возникнуть три вида проблем:
- Грязное чтение (dirty read) - одна транзакция видит измененные данные другой незавершенной транзакции
- Неповторяющееся чтение (nonrepeatable read) - один и тот же запрос в рамках транзакции возвращает разные результаты
- Фантомное чтение (phantom read) - один и тот же запрос в рамках транзакции возвращает разное число записей
И есть у нас 4 уровня изоляции
- Read Uncommitted (в постгре его нет) - возможно возникновение всего на свете
- Read Committed - по умолчанию - исключает возможность грязного чтения
- Repeatable Read - исключает еще и неповторяющееся чтение (в постгре на самом деле и фантомку тоже из-за MVCC, но по стандарту нет. А вот аномалии сериализации никуда не делись)
Аномалии сериализации - параллельные транзакции дают результат, которых невозможен, если бы они выполнялись по очереди. В постгре для Serializable используется SSI, помогающий этого избежать - Serializable - максимальная изоляция и симуляция поведения как при последовательном выполнениии, так что исключает все проблемы
Snapshot Isolation (SI)
- Снимок (снапшот) - характеризует временное окно видимости данных для транзакции
- Каждая транзакция видит свой свой набор данных, определяемый связанным с ней снимком
- Снимок: какие xid (версии данных) видит данная транзакция
- Можно указать через
pg_current_snapshot()
pg_current_snapshot() (txid_current_snapshot())- возвращает текущий снимок- Формат: xmin:xmax:xid1,xid2
- Верхняя граница не включается
- Снапшот предоставляется мэнеджером транзакций
- Read Committed - свой снимок для каждого sql предложения
- Repeatable Read, Serializable - только при выполнении первого SQL предложения
- Выбор подходящей версии определяется по правилам проверки видимости, которые используют
- Снимок
- Значения xmin, xmax, cmin, cmax,....
VACUUM
Реализация транзакций в постгре - MVCC
Multi-Version Concurrency Control
В постгре - Serializable Snapshot Isolation (SSI)
Особенность в том, что при изменении данных в транзакции создается новая копия данных. А существующие копии не изменяются. Надо что-то делать!
А что делать? А удалять) И для удаления таких записей и используется VACUUM
VACUUM table [table 2]
VACUUM
- по умолчанию - чистит, но без сжатия
- VACUUM FULL - чистит со сжатием
VACUUM FREEZE - замораживает старые строки чтоб они больше не зависели от xid чтоб избежать его переполнения. Помеченная FROZEN строка считается оч старой, всегда видима всем и не зависит от xid
avtovacuum
по умолчанию true
меняется в postgresql.conf autovacuum_vacuum_threshold- минимальное число изменений, после которого есть смысл запускатьautovacuum_vacuum_scale_factor- процент от размера таблицы, т.е. сколько процентов строк надо изменитьautovacuum_cost_limit- ограничивает интенсивность работы, указывая - сколько единиц может потратить процесс (чтобы у нас к чертям не полетела производительность).
Выполнение операций и восстановление данных
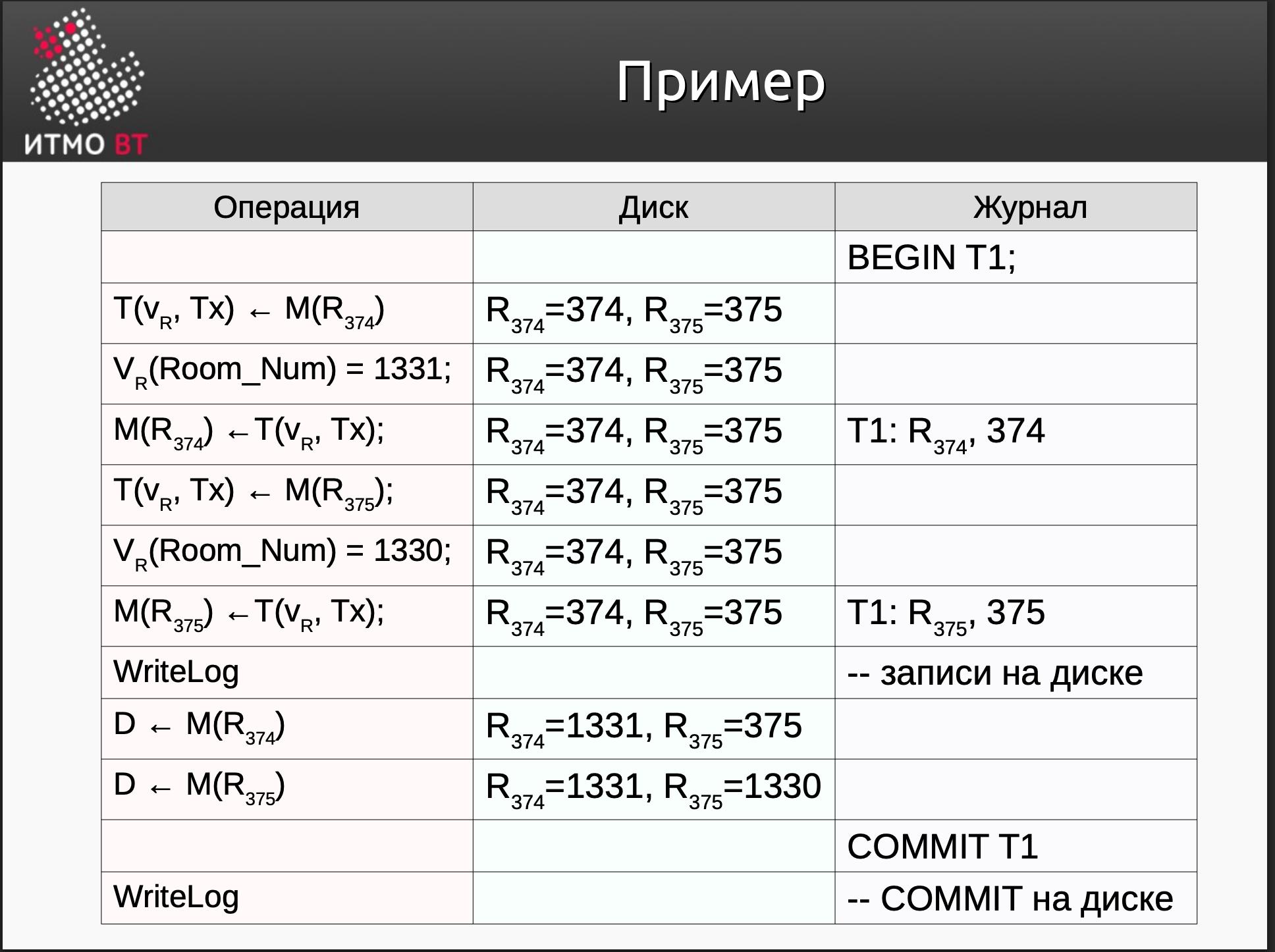
M - memory, D - disk, T - transaction
Операции для синхронизации различных пространств памяти:
M <- D(Obj)- загрузить страницу, содержащую объект с диска в буферное пространствоD <- M(Obj)- сохранить страницу с объектом на диск из буфераT(v, Tx) <- M(Obj)- копировать obj в переменную v транзакции Tx- Если объект не в M, то сначала M <- D(Obj)
M(Obj) <- T(v, Tx)- копировать значение v из транзакции Tx в Obj.- Если объект не в M, то сначала M <- D(Obj)
WriteLog- сохранить лог на диск из соответствующего буфера
А чего мы будем делать, если у нас случится незапланированный отказ работы экземпляра, а у нас идет выполнение?
Для предотвращения ситуаций, связанных с появлением несогласованных данных можно использовать журнал (лог)
СУБД сохраняет информацию об изменениях и фиксациях данных в журнале:
- Сначала запись сохраняется в соответствующем буфере (буфере журнала)
- Буфер журнала синхронизируется с файлами журнала на диске (WriteLog)
UNDO-журнал
Возможные записи в журнале отмены:
BEGIN Tx- начало транзакцииTx: R, old_val- изменение: транзакция Tx переписывает значение old_val в RCOMMIT Tx- успешное завершение транзакцииABORT Tx- преждевременное завершение транзакцииSTART CHKn- начало создания контрольной точки- E
ND CHKn- завершение создания контрольной точки
Правила записи в UNDO LOG
- Запись изменения данных записывается в журнал (на диск) до сохранения обновленного значения на диске.
- COMMIT Tx должен быть добавлен в журнал (на диск) после обновления всех файлов данных, связанных с изменениями данной транзакции (после синхронизации буферного пространства данных с файлами данных)
Пример:
Использование журнала отмены для восстановления данных
- СУБД сканирует журнал от новых записей до старых. Отдельно фиксируются транзакции.
- Группа 1: для которых есть запись COMMIT Tx
- Группа 2: транзакции, для которых есть запись ABORT Tx, незавершенные транзакции
- Когда в журнале встречается запись изменения, анализируется Tx
- Если она из группы 1 - действия не предпринимаются
- Если из группы 2 - для R восстанавливается old_val (происходит отмена)
- СУБД записывает ABORT Tx для каждой незавершенной транзакции из группы 2
- Запускается операция WriteLog, чтобы записи вида ABORT Tx оказались в журнале
Контрольные точки
Для восстановления данных нужна какая-то стартовая точка, чтобы не анализировать транзакции с самого начала работы с БД.
Контрольная точка (checkpoint) - точка синхронизации, во время которой происходит синхронизация данных из буферов с соответствующими файлами на диске
Создаются они так:
- В журнал добавляется START CHKn: , фиксируется на диске через WriteLog
- Ожидание завершения транзакций, которые работали в момент создания КТ. В это время могут начинаться другие транзакции
- В журнал добавляется END CHKn, фиксируется на диске
- Записи перед START CHKn, у которой есть END CHKn могут быть удалены
Действия при восстановлении данных:
- СУБД сканирует журнал и встречает запись END CHKn: Tn...Tm
- Это значит, что установка кт n завершена
- Сканирование журнала до записи START CKn, так как незавершенные транзакции могут быть только после записи START CHKn
- среди транзакций, которые начали работу после начала установки контрольной точки
- остальные действия как раньше
- СУБД сканирует журнал и встречает запись START CHKn
- Установка КТ не завершена (проблема во время установки)
- Сканирование журнала до первой записи из самой ранней транзакции среди T_n ... Tm:
- Такая запись будет до START CHKn
- Остальные действия как раньше
Для тех, кто ничего не понял:
Контрольная точка используется для сокращения объёма журнала, необходимого для восстановления, чтобы не читать лог с самого начала. Она создаётся по времени, по объёму WAL или вручную.
При записи START CHK фиксируется список активных транзакций. Затем система ожидает их завершения (COMMIT или ABORT), после чего записывается END CHK, означающий успешное завершение контрольной точки.
После завершения checkpoint можно удалять устаревшие записи журнала, относящиеся к более ранним контрольным точкам.
При восстановлении возможны два сценария:
- если найдена запись END CHK, восстановление начинается с соответствующей записи START CHK;
- если запись END CHK отсутствует, checkpoint считается незавершённым, и восстановление продолжается дальше по журналу до более ранних записей.
Недостатки UNDO LOG
- Нельзя завершить транзакцию (зафиксировать коммит в журнале) до записи изменений данных в файлы данных
- Много операций ввода-вывода с диском, тк надо синхронизировать данные для каждой транзакции
REDO-журнал
Возможные записи в журнале повторений:
BEGIN Tx- начало транзакцииTx: R, new_val- изменение: транзакция Tx изменяет значение на new_val в RCOMMIT Tx- успешное завершение транзакцииABORT Tx- преждевременное завершение транзакцииSTART CHKn- начало создания контрольной точки- E
ND CHKn- завершение создания контрольной точки
Правила записи в REDO LOG
- Запись изменения данных записывается в журнал (на диск) до сохранения обновленного значения на диске.
- COMMIT Tx должен быть добавлен в журнал (на диск) до обновления любого из файлов данных, связанных с изменениями данной транзакции (после синхронизации буферного пространства данных с файлами данных)
- Т.е. в WAL (на диске) вносятся записи изменения, которые произошли в Tx и только потом идет синхронизация буферов с диском.
Пример:
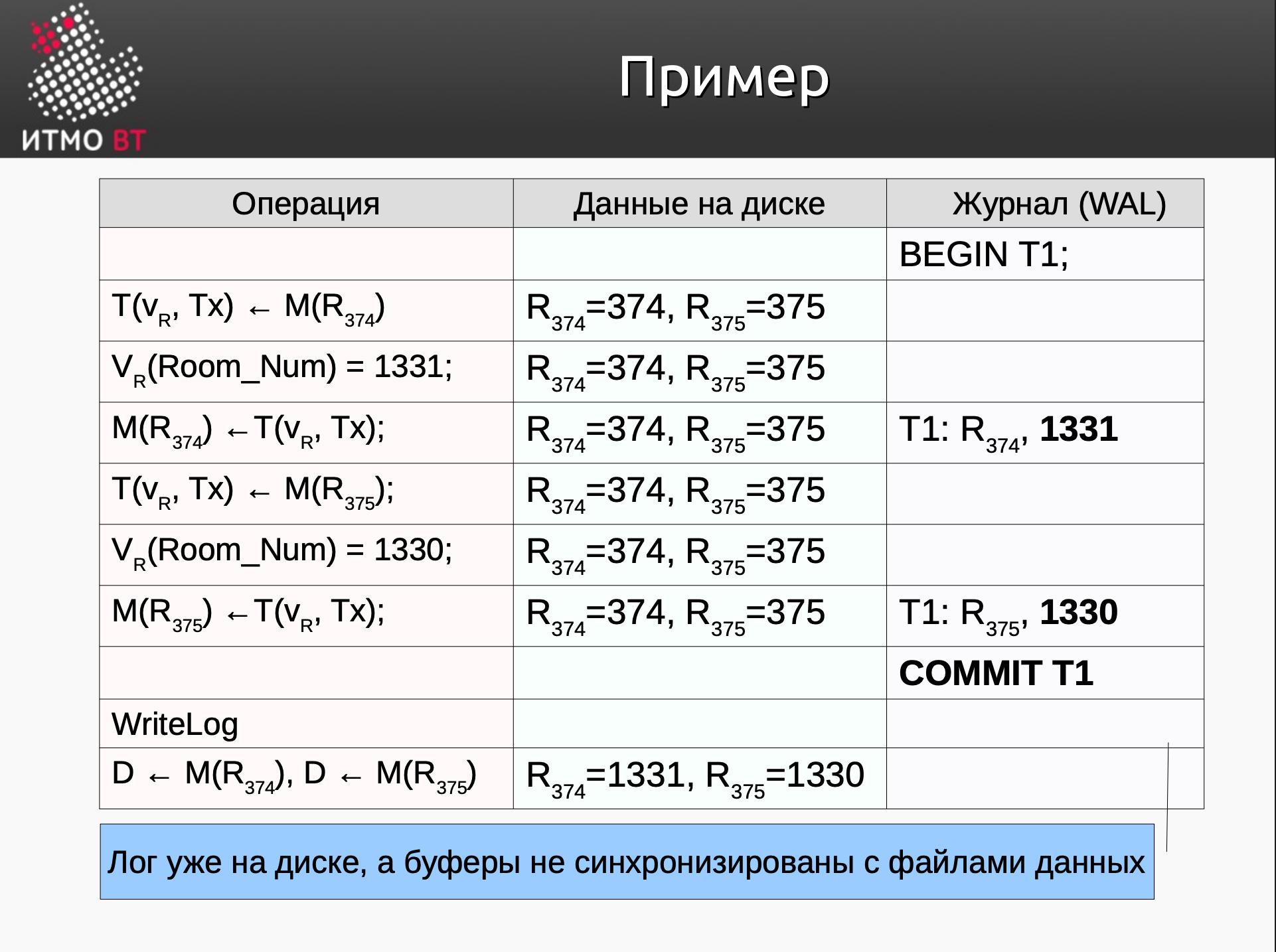
Использование журнала повторений для восстановления данных
- СУБД сканирует журнал от старых записей до новых. Отдельно фиксируются транзакции.
- Группа 1: для которых есть запись COMMIT Tx
- Группа 2: транзакции, для которых есть запись ABORT Tx, незавершенные транзакции
- Когда в журнале встречается запись изменения, анализируется Tx
- Из группы 1: для R перезаписывается new_val
- Из группы 2: СУБД записывает ABORT Tx для каждой незавершенной транзакции из группы 2. Запускается WriteLog чтоб записи вида ABORT оказались в журнале
Контрольные точки
Контрольная точка в REDO используется для сокращения объёма журнала при восстановлении.
При её создании сначала записывается START CHK со списком активных транзакций, затем происходит запись на диск всех “грязных” страниц, относящихся к завершённым транзакциям, и после этого фиксируется END CHK.
Checkpoint не ожидает завершения активных транзакций.
При восстановлении:
- если найден END CHK, обработка начинается с соответствующего START CHK;
- если END CHK отсутствует, checkpoint считается незавершённым, и используется предыдущая контрольная точка.
Недостатки REDO LOG
- Нельзя сбросить данные из буферов на диск до завершения транзакции, так что требуется много памяти под буферы
UNDO/REDO-журнал
Возможные записи:
Возможные записи в журнале повторений:
BEGIN Tx- начало транзакцииTx: R, old_val, new_val- изменение: транзакция Tx изменяет значение на new_val в RCOMMIT Tx- успешное завершение транзакцииABORT Tx- преждевременное завершение транзакцииSTART CHKn- начало создания контрольной точки- E
ND CHKn- завершение создания контрольной точки
Правила записи в REDO LOG
- Запись изменения данных записывается в журнал (на диск) до сохранения обновленного значения на диске.
- COMMIT Tx может быть добавлен в журнал (на диск) как до, так и после обновления любого из файлов данных, связанных с изменениями данной транзакции
Использование для восстановления данных
- Повторить операции для завершенных транзакций (от ранних к поздним)
- Отменить операции для незавершенных транзакций (от поздних к ранним)
- Запись COMMIT должна быть сразу синхронизирована с журналом
Контрольные точки
При создании записывается START CHK со списком активных транзакций, затем на диск сбрасываются все “грязные” страницы, включая данные незавершённых транзакций, после чего записывается END CHK.
Checkpoint не ожидает завершения транзакций.
При восстановлении:
- если найден END CHK, анализ начинается с соответствующего START CHK;
- если END CHK отсутствует, используется более ранняя точка журнала.
Далее выполняются фазы анализа, повторения (REDO) и отката (UNDO).
steal/no-steal, force/no-force
- no-steal - подход, при котором страница из буфера данных не может быть записана на диск до коммита (завершения транзакции), в ходе которой она была изменена
- steal - если позволено записывать в файлы данных данные еще незавершенных транзакций (для оптимизации запросов к диску или если буферная память заканчивается)
- force - если требуется, чтобы все страницы, измененные транзакцией, записывались сразу перед COMMIT
- no-force - изменения, осуществленные завершенными транзакциями могут быть не зафиксированы на диске
steal про то, можно ли писать на диск незавершенные транзакции
force про то, нужно ли при коммите писать на диск все изменения
В постгре steal + no-force потому что быстрее, меньше ввода-вывода и лучше масштабируется (зато долбежка с восстановлением в виде WAL + ARIES)
ARIES - алгоритм для восстановления данных, который базируется на
wal + steal + no-force
Происходит в три этапа:
- Анализ - поиск грязных страниц и незавершенных транзакций
- REDO - повторение всех действий
- UNDO - откат действий незавершенных транзакций
Для работы требуется LSN, таблица транзакций и таблица грязных страниц.
Резервное копирование
Стратегия РК:
- полная - охватывает всю бд
- частичная - охватывает только часть бд
РК может содержать: - все страницы в пределах выбранных файлов
- ту информацию, которая изменилась с момента последнего рк (инкрементарная)
- кумулятивная - изменения до последнего уровня 0
- дифференциальная - изменения до последнего инкрементального рк
Виды РК:
- холодное - создание рк, когда экземпляр сервера бд остановлен
- горячее - сервер работает
Логическое РК
- Копируется не сама БД, а ее логическое представление
- Результат - SQL-скрипт, который может воссоздать состояние БД
- Файлы данных (PGDATA) не копируются
Содержит: - Команды создания объектов
- CREATE TABLE
- CREATE INDEX
- данные
- INSERT или COPY
- иногда
- CREATE DATABASE
- GRANT, роли (в случае pg_dumpall)
Основные утилиты:
- pg_dump - дамп одной бд или ее части
- pg_dumpall - дамп всего кластера включая роли
- pg_restore - восстановление из нестандартных форматов
Пример:
pg_dump mydb > dump.sql
pg_dump -Fc -f dump mydb
pg_restore -d mydb dump
pg_dump
Форматы pg_dump:
- plain
- текстовый SQL
- можно выполнить через psql
- custom (-Fc) - бинарник с поддержкой выборочного восстановления
- directory (-Fd) - отдельные файлы на таблицы -->
- в директории есть файл toc.dat: индекс для pg_restore + для поиска файлов внутри директории
- tar (-Ft) - архив
Особенности использования: - по умолчанию не создаются предложения для создания БД
- для восстановления надо подключиться к существующей
- для добавления создания бд надо флаг -C
При создании дампа можно указать флаги для восстановления конкретных элементов: - -t tableName - только эта таблица
- -T tableName - все кроме этой таблицы
- -a - только data
- -s - только схема
Для восстановления:
psql mydb < mydbdump- использующиеся в бэкапе пользователи, роли должны существовать до запуска скрипта
pg_restore -d mydb mydbdump
pg_dumpall
- утилита для создания скрипттов восстановления всех бд в кластере
pg_dumpall -U postgres1 -f mydbdump
- создает sql-скрипт
- кроме бд сохранятся глобальные объекты
- Восстановление:
psql -f dumpfile postgres
Плюсы РК
- переносимость
- гибкость
- удобно для миграций
Минусы
- медленно для больших бд
- нет моментального снимка файлов
- не подходит для больших объемов
Физическое РК
- Копируются файлы БД
- результат - копия PGDATA
- включает:
- таблицы
- индексы
- системные файлы
Подходы:
Копирование фс
Полное копирование PGDATA. Обычно на холодную или через снапшот данных. Копируется ток вся бд целиком, выбрать отдельные таблицы нельзя
Непрерывное архивирование
- Базируется на существовании WAL
- состояние бд может быть восстановлено путем повтора зафиксированных в логе операций.
- Конфигурационные файлы не восстанавливаются через WAL
РК = полная копия + WAL-files
Физическое РК + WAL
- бд не обязательно в полностью согласованном состоянии
- для приведения состояния к согласованному может использоваться wal
- с точки зрения работы wal - механизмы аналогичны тем, которые используются при восстановлении после сбоев
- можно восстановить данные в одно из временных состояний между снятием бэкапа и последним wal
- можно восстановить бд целиком, а не отдельную часть
Этапы для реализации непрерывного архивирования
- Организация архивирования WAL
- Создание базовой резервной копии
Этап 1:
- WAL на диске разделен на сегменты по 16Мб
- Необходимо осуществить копирование добавляемых сегментов на внешнее хранилище.
- Для включения возможности рк:
- archive_mode = on
- wal_level = replica
archive_command =cp %p/path2/%fгде %p - заменяется на полное имя файла для архивирования, %f - заменяется на имя файла - команда для копирования сегментов WAL в path2
Этап 2:
pg_basebackup
pg_basebackup -D /backup
Делает физическую копию кластера, может работать из запущенной бд, используется для репликации.
pg_start_backup / pg_stop_backup
SELECT pg_start_backup('label');
-- создается backup_my_label файл, который содержит инфу о рк
-- создается КТ и tablespace_map
-- пользователем производится копирование файлов кластера БД
SELECT pg_stop_backup();
инициализирует бэкап режим, создает чекпоинт и фиксирует консистентное состояние
Восстановление
- Остановить сервер
- Если возможно - сделать копию хотя бы pg_wal
- Проверить наличие бэкапа. Если есть - удалить PGDATA и внешние директории (если есть)
- Скопировать в PGDATA и внешние директории данные ранее полученного бэкапа
- Очистить PGDATA/pg_wal
- Если есть незаархивированные WAL c шага 2 - поместить их в pg_wal
- Установить настройки для восстановления в postgresql.conf (restore_command возвращает не 0 при неудаче) + запретить внешние подключения для юзеров в pg_hba.conf
- Создать файл recovery.signal - говорит серверу, что надо стартовать в режиме восстановления
- Запустить сервер
- Разрешить подключение пользователей
restore_command
- Задает логику получения архивированных WAL файлов
- archive_command =
cp /path2/%f %pгде %p - путь, куда копировать файлы (wal-сегменты), %f - имя файла (wal-сегмента) - Сегменты, которые не были найдены в архиве, будут искаться в pg_wal
- приоритет тем сегментам, которые в архиве
Репликация
Репликация — процесс дублирования данных с одного сервера базы данных на другие для повышения надежности, обеспечения отказоустойчивости и балансировки нагрузки.
Виды репликации
По способу синхронизации (отправки подтверждения):
- Асинхронная — мастер отправляет подтверждение транзакции (коммита) клиенту сразу после локального сохранения, а данные отправляются на реплику в фоне.
- Плюсы: Ниже задержка для мастера и клиентов.
- Минусы: Есть риск потери данных при падении ведущего узла, так как реплика может незначительно отставать.
- Синхронная — мастер ждет подтверждения от реплики о получении/сохранении данных перед тем, как ответить клиенту, что транзакция завершена.
- Плюсы: Гарантия сохранности данных (нет потери при отказе мастера).
- Минусы: Выше задержка транзакций (зависит от сети и реплики).
По передаваемым данным:
- Физическая — побитовое копирование файлов и страниц памяти.
- Логическая — репликация на уровне команд (операций DML) или строк.
Физическая репликация в PostgreSQL
Основана на передаче файлов WAL (Write-Ahead Log) от ведущего сервера к потоковой реплике (Standby).
Реплика находится в режиме постоянного восстановления (Continuous Recovery) и непрерывно применяет приходящие WAL.
Ключевые настройки:
wal_level = replica(илиlogical) — задает объем данных, сохраняемых в WAL (минимально необходимый для работы реплики).wal_keep_size(ранееwal_keep_segments) — объем WAL на резерве (в MB), который мастер не будет удалять, чтобы временно отключившиеся реплики могли "догнать" мастера после возобновления связи.- Слоты репликации (Replication slots) — механизм, который защищает WAL-файлы нужные репликам. Используя слот, мастер гарантирует, что не удалит необходимые WAL-файлы, даже если реплика отключена долгое время (в отличие от
wal_keep_size, слоты могут переполнить диск мастера, если реплика "умерла" навсегда).
Логическая репликация в PostgreSQL
Основывается на логическом декодировании (Logical Decoding) — разборе потока WAL в понятные логические операции.
- Работает по архитектуре Publisher-Subscriber (издатель-подписчик). Мастер выступает как издатель (
PUBLICATION), реплика — как подписчик (SUBSCRIPTION). - Можно реплицировать не весь кластер, а лишь отдельные таблицы.
- Позволяет выполнять запись в таблицы реплики (которые не реплицируются) и осуществлять репликацию между базами с разными мажорными версиями PostgreSQL.
Различные топологии и подходы
- Master/Slave (Primary/Standby) — классическая архитектура. Одна нода главная и принимает запросы на запись/чтение, остальные — только читают.
- Ступенчатая (каскадная) репликация — Мастер передает WAL реплике A, а реплика A передает этот же WAL реплике B. Это позволяет снизить нагрузку на сеть и I/O мастера.
- Master/Master (Двунаправленная) — две или более ноды могут принимать как чтение, так и запись.
- Плюсы: Масштабирование записи.
- Минусы: Проблемы с разрешением конфликтов параллельной записи (если на двух узлах обновили одну строку). В PostgreSQL реализуется специальными расширениями (например, BDR).
- Репликация без ведущего узла (Peer-to-Peer / Multi-master) — все узлы равны, нет выделенного мастера. Часто применяется в NoSQL (DynamoDB, Cassandra) с использованием кворумов.
- Триггерная репликация — логический подход, применявшийся до появления встроенных механизмов lógico-репликации в PostgreSQL. При изменениях срабатывали триггеры, писали информацию в специальную таблицу очередей, которая далее транслировалась (Slony, Londiste, Bucardo).
- High Availability (HA) — Высокая доступность. Это концепция, где за счет репликации и инструментов-координаторов автоматически происходит переключение при сбое (Failover/Switchover) на рабочие реплики для бесперебойной работы приложения (инструменты типа Patroni).
- Конечная согласованность (Eventual Consistency) и Задержка (Replication Lag). В асинхронных системах изменения на реплике применяются с некоторой задержкой (lag). Из-за этого при чтении с реплики данные могут быть устаревшими на доли секунды, но со временем они придут в консистентное состояние.
CAP теорема
В распредёленной системе невозможно одновременно обеспечить все три свойства, нужно выбрать два:
- Consistency (Согласованность) — каждый клиент получает только последние записанные данные, независимо от того, к какому узлу обращается.
- Availability (Доступность) — каждый запрос получает не-отказный ответ, хотя данные могут быть устаревшими.
- Partition tolerance (Устойчивость к разделению) — система продолжает работать при распадах сети и потере связи между узлами.
В условиях сетевых разделений придется выбирать между CP и AP.
Масштабирование и шардирование
Масштабирование — процесс расширения адаптационных возможностей БД при росте нагрузки (увеличении объема данных и количества запросов).
- Вертикальное масштабирование (Scale-Up) — добавление ресурсов (CPU, RAM, быстрые диски) в один текущий сервер. Просто в реализации (не требует изменения логики БД), но имеет потолок возможностей и становится непропорционально дорогим на больших объемах.
- Горизонтальное масштабирование (Scale-Out) — распределение нагрузки путем добавления новых серверов (узлов) в кластер. Снижает зависимость от железа и потенциально безгранично, но требует изменения архитектуры и применения шардирования.
Шардирование
Шардирование (Sharding) — метод горизонтального масштабирования, при котором данные логически одной базы (например, гигантская таблица) разделяются по кускам (шардам) и хранятся на различных независимых узлах.
- Ключ шардирования (Shard Key) — поле (или набор полей), по которому система определяет, в каком из шардов должна лежать конкретная строка (например,
user_id). - Позволяет распределить как нагрузку на чтение, так и логику записи.
Перебалансировка (Rebalancing) при шардировании
Процесс миграции данных между шардами, например, при добавлении в кластер новых серверов для поддержания баланса.
Методы балансировки зависят от способа логического деления ключа (Hash, Range, List), но зачастую перенос больших кусков данных (при изменении числа серверов) является сложной алгоритмической и эксплуатационной задачей.
Ассиметричное шардирование
Возникает из-за дисбаланса, когда некоторые шарды перегружаются запросами по сравнению с остальными.
Чаще всего вызвано наличием горячих диапазонов ("hot spots") или неравномерным хэшированием ключа.
Способы решения данной проблемы:
- Консистентное хеширование (Consistent Hashing) — данные распределяются по так называемому "кольцу хэшей", и при добавлении/удалении нового узла переносится только малая часть данных от соседнего узла к новому, не затрагивая весь кластер.
- Виртуальные бакеты / виртуальные узлы — разделение данных на огромное количество логических фрагментов (гораздо больше, чем серверов) и гибкий маппинг этих виртуальных бакетов в физические серверы. При необходимости логически перекидываются целые бакеты без затрагивания функции хэширования.
- Использование "соли" (salting) к ключу шардирования для более равномерного распределения горячих данных.